Failures during IBC Transfers and Swaps
There are two types of IBC failures that may occur when a user attempts to traverse a swap / transfer route produced by the Skip Go API.- Pre-Swap / swap failures
- What: These are failures in the sequence of ICS-20 transfers leading up to the swap or a failure in the swap itself (usually due to slippage).
- Outcome / What to Expect: The users’ original source tokens are returned their starting address on the source chain
- Common causes:
- Inactive relayers on a channel allow a packet to timeout
- Slippage (the amount out for the swap turns out to be less than the user’s specified minimum, i.e. their slippage exceeds their tolerance)
- The user / frontend provides an invalid recovery address
- An IBC client on the destination chain has expired
- Examples: Consider a route where the source asset is ATOM on Neutron, the destination asset is STRIDE on Stride, and the swap takes place on Osmosis:
- The user’s tokens transfer from Neutron to the Hub to Osmosis. The swap initiates but the price of STRIDE has gotten so high that the swap exceeds slippage tolerance and fails. A sequence of error acks is propagated back to the Hub then Neutron, releasing the user’s ATOM to their address on Neutron where they started
- The user attempts to transfer tokens from Neutron to the hub, but the packet isn’t picked up by a relayer for more than 5 minutes (past the timeout_timestamp). When a relayer finally comes online, it relays a timeout message to Neutron, releasing the user’s ATOM back to their address on Neutron where they first had it.
- For transfer-only routes: This is the only kind of failure that may happen on a route that only contains transfers. Either the user’s tokens will reach their destination chain as intended, or they will wind up with the same tokens, on the same chain where they started.
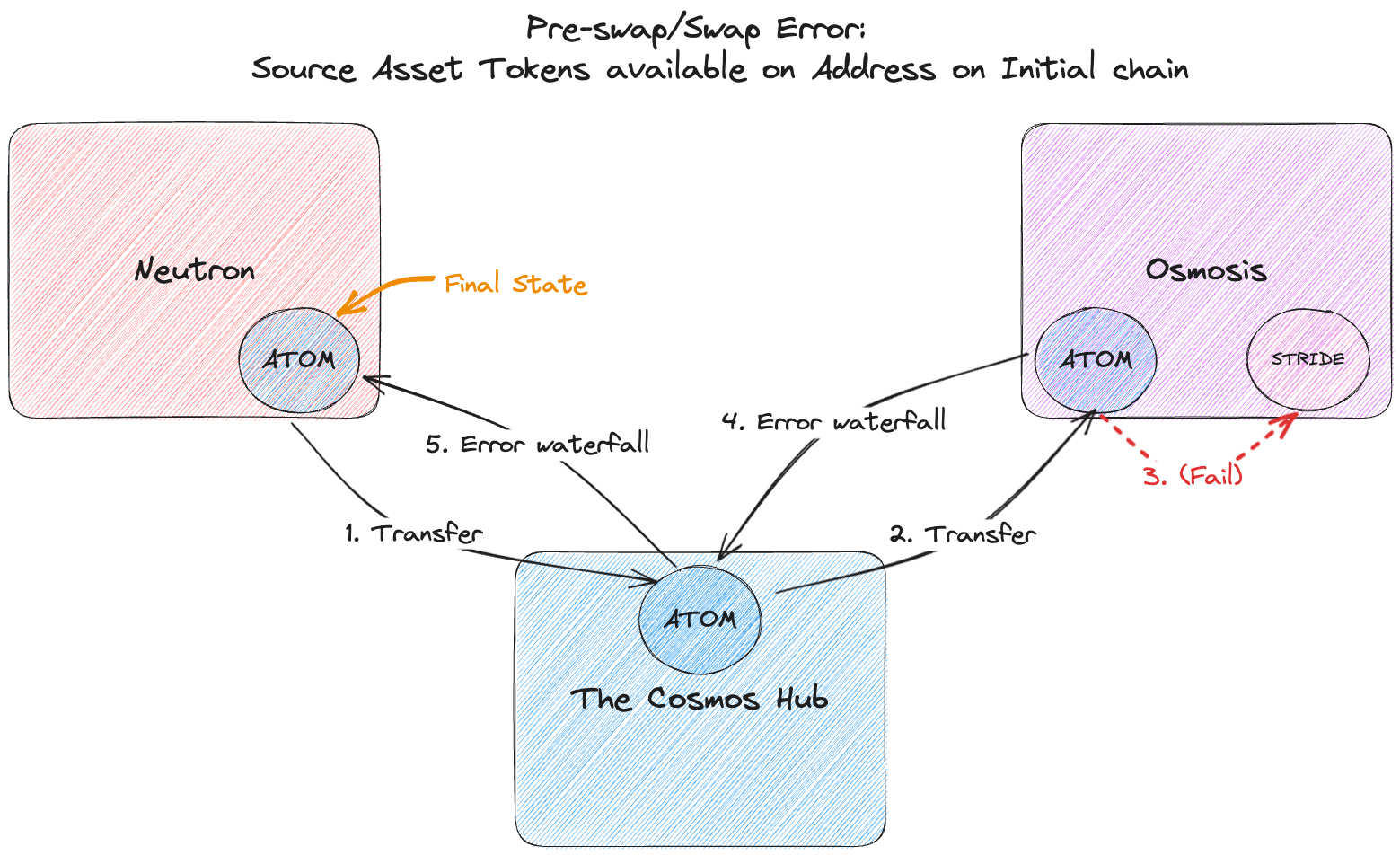
In a pre-swap or swap related error, the user will end up with the same tokens they started with on their initial chain (e.g. ATOM on Neutron in this example)
- Post-swap failures:
- Description: These are failures that occur on the sequence of transfers between the swap venue chain and the user’s destination chain, after the user’s origin tokens have already been successfully swapped for their desired destination asset.
- Outcome / What to Expect: The user’s newly purchased destination asset tokens will be transferred to their address on the swap chain. (This is the address passed to
chains_to_addressesin/fungible/msgsfor the chain where the swap takes place, which is given byswap_venue.chain_idin the response from/fungible/route) - Common failure sources:
- Inactive relayers on a channel allow a packet to timeout
- The user / frontend provides an invalid address for the destination chain
- An IBC client on the destination chain has expired
- Examples: Consider a route where the source asset is ATOM on Neutron, the destination asset is STRIDE on Stride, and the swap takes place on Osmosis:
- Suppose the swap took place and the transfer to Stride has been initiated, but the Relayer between Osmosis and Stride is down. So the packet’s timeout occurs after 5 minutes. When the Relayer comes back online after 8 minutes, it relays a timeout message to Osmosis, releasing the user’s STRIDE, which gets forwarded to their Osmosis address
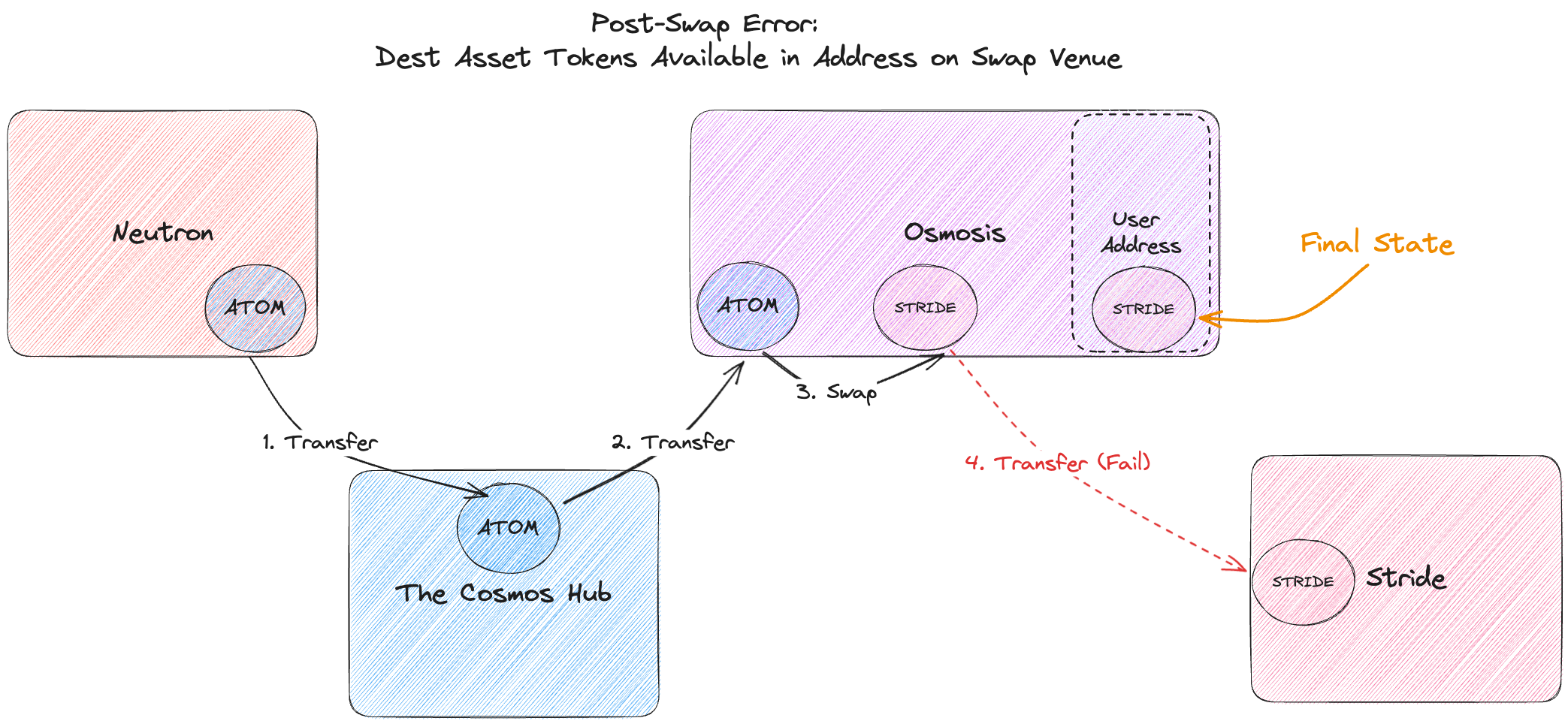
In a post-swap error, the user will end up with their destination asset tokens in their address on the chain where the swap took place (e.g. STRIDE on Osmosis in this example)
Axelar Failures
Axelar transfers can be tracked on Axelarscan. Often, Axelar transfers are delayed by Axelar’s relayer or execution services. If a transaction is taking longer than expected, users can visit Axelarscan, find their transaction, and manually execute the steps needed to get the transfer through. See the Axelar docs for details on how to use Axelarscan. Internally, the Skip Go API may use Axelar’s General Message Passing service to move assets between EVM and Cosmos. There are similar failure modes for Axelar as there are for IBC:- Swap failures
- What: Axelar GMP takes user assets from an EVM chain to the swap chain. The swap can still fail at this point due to a timeout or slippage.
- Outcome / What to Expect: The user receives the Axelar-transferred token on the chain where the swap was supposed to take place at their recovery address. (Note this is different from the IBC swap failure case where the user receives the swap token back on the source chain)
- Common failure sources:
- Slow relaying from Axelar causes a timeout, and the swap is not attempted.
- Slippage (the amount out for the swap turns out to be less than the user’s specified minimum, i.e. their slippage exceeds their tolerance)
- Post-swap failures
- Once the swap is executed, Axelar is no longer involved, and the same rules that apply to IBC post-swap failures apply here, so the Post-swap failures section above applies.
CCTP Failures
Routes that use CCTP transfers rely on Circle to produce attestations. The Circle attestation service waits for a specified number of on-chain block confirmations before producing an attestation. The number of block confirmations required is specified by Circle in their documentation here. If Circle’s attestation service experiences an outage, malfunction, or otherwise becomes unresponsive, CCTP transfers will continue to burn assets on the source chain, but will not be able to mint assets on the destination chain. In this case, funds that have been burned to initiate a CCTP transfer will be inaccessible until the Circle attestation service recovers.Hyperlane Failures
Each Hyperlane token transfer route is secured by an Interchain Security Module (ISM) designated by the deployer of the Hyperlane Warp Route Contracts (the interface to send tokens across chains using Hyperlane). The ISM defines the requirements for a message to be successfully processed on the destination chain. The most common ISM is a Multisig ISM where “Validators” of a specific Hyperlane route sign attestations that a specific message on an origin chain is a valid message to be processed on the destination chain. In the case where the set of Validators have not hit the required signature threshold to successfully process a Hyperlane message on the receiving chain, funds will not be accessible by the user on either chain until the threshold is met (once met, funds will be sent to the user on the destination chain). This generalizes to the different requirements for different ISMs. The Hyperlane documentation explains the different types of ISMs in more detail: https://docs.hyperlane.xyz/docs/reference/ISM/specify-your-ISMGo Fast Failures
If a transfer timeout occurs, meaning a user’s intent does not receive a response from solvers within a predefined time frame, the solver initiates a refund process to ensure that users do not lose funds. Here’s a breakdown of what happens in the event of a timeout:-
Intent Expiration: When a user initiates an intent by calling the
submitOrderfunction on the source chain, a time limit is specified. Solvers monitor the intent and assess whether they can fulfill it within this period. If no solver fills the intent before the timeout, the refund process begins. - Refunds: Once the timeout period is reached without fulfillment, the solver calls a function on the contract to trigger a refund process. This is handled on-chain, and includes any fees initially allocated from the user for solver compensation.
We’re working to make these failures even less common
- In the short term, we’re working to add packet tracking + live relayer + client status to the API to help identify when packets get stuck and prevent folks from using channels where they’re likely to get stuck in the first place
- In the medium term, we are working to add priority multi-hop relaying into the API.
- In the long term, we’re working to build better incentives for relaying, so relayers don’t need to run as charities. (Relayers do not receive fees or payment of any kind today and subsidize gas for users cross-chain)
Have questions or feedback? Help us get better!Join our Discord and select the “Skip Go Developer” role to share your questions and feedback.